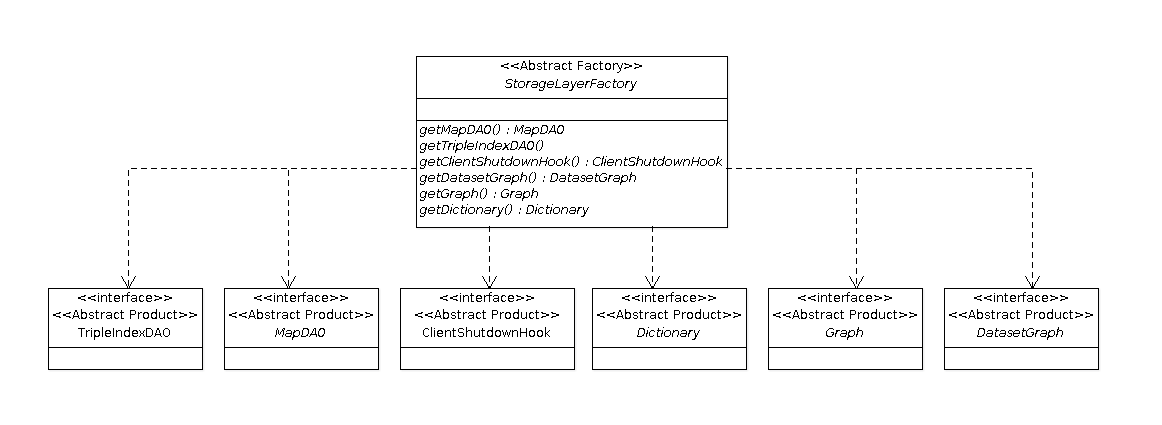
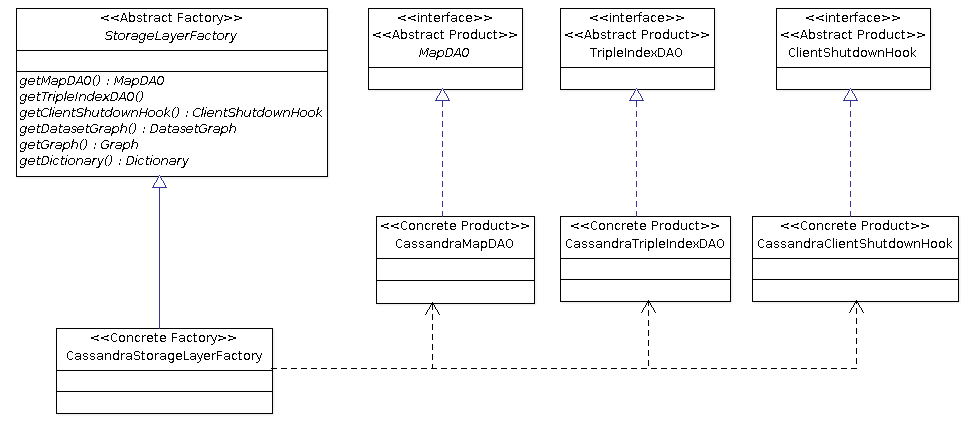
In a preceding post I described how to quickly set-up a standalone SolRDF instance in two minutes; here, after some work more or less described in this issue, I'll describe in few steps how to run SolRDF in a simple cluster (using SolrCloud). The required steps are very similar to what you (hopefully) already did for the standalone instance.
All what you need
- A shell (in case you are on the dark side of the moon, all steps can be easily done in Eclipse or whatever IDE)
- Java 7
- Apache Maven (3.x)
- Apache Zookeeper (I'm using the 3.4.6 version)
- git (optional, you can also download the repository from GitHub as a zipped file)
Start Zookeeper
Open a shell and type the following
# cd $ZOOKEPER_HOME/bin
# ./zkServer -start
That will start Zookeeper in background (start-foreground for foreground mode). By default it will listen on localhost:2181
Checkout SolRDF
If it is the first time you hear about SolRDF you need to clone the repository. Open another shell and type the following:
# cd /tmp
# git clone https://github.com/agazzarini/SolRDF.git solrdf-download
Alternatively, if you've already cloned the repository you have to pull the latest version, or finally, if you don't have git, you can download the whole repository from here.
Build and Run SolRDF nodes
For this example we will set-up a simple cluster consisting of a collection with two shards.
# cd solrdf-download/solrdf
# mvn -DskipTests \
-Dlisten.port=$PORT \
-Dindex.data.dir=$DATA_DIR \
-DskipTests \
-Dulog.dir=ULOG_DIR \
-Dzk=ZOOKEEPER_HOST_PORT \
-Pcloud \
clean package cargo:run
Where
- $PORT is the hosting servlet engine listen port;
- $DATA_DIR is the directory where Solr will store its datafiles (i.e. the index)
- $ULOG_DIR is the directory where Solr will store its transaction logs.
- $ZOOKEEPER_HOST_PORT is the Zookeeper listen address (e.g. localhost:2181)
[INFO] Jetty 7.6.15.v20140411 Embedded started on port [8080]
[INFO] Press Ctrl-C to stop the container...the first node of SolRDF is up and running!
(The command above assume the node is running on localohost:8080)
The second node can be started by opening another shell and re-executing the command above
# cd solrdf-download/solrdf
# mvn -DskipTests \
-Dlisten.port=$PORT \
-Dindex.data.dir=$DATA_DIR \
-DskipTests \
-Dulog.dir=ULOG_DIR \
-Pcloud \
cargo:run
Note:
- "clean package" options have been omitted: you've already did that in the previous step
- you need to declare different parameters values (port, data dir, ulog dir) if you are on the same machine
- you can use the same parameters values if you are on a different machine

(Distributed) Indexing
Open another shell and type the following (assuming a node is running on localhost:8080):
# curl -v http://localhost:8080/solr/store/update/bulk \
-H "Content-Type: application/n-triples" \
--data-binary @/tmp/solrdf-download/solrdf/src/test/resources/sample_data/bsbm-generated-dataset.nt
Wait a moment...ok! You just added 5007 triples! They've been distributed across the cluster: you can see that by opening the administration consoles of the participating nodes. Selecting the "store" core of each node, you can see how many triples have been assigned to that specific node.

Querying
Open another shell and type the following:
# curl "http://127.0.0.1:8080/solr/store/sparql" \
--data-urlencode "q=SELECT * WHERE { ?s ?p ?o } LIMIT 10" \
-H "Accept: application/sparql-results+json"
...
# curl "http://127.0.0.1:8080/solr/store/sparql" \
--data-urlencode "q=SELECT * WHERE { ?s ?p ?o } LIMIT 10" \
-H "Accept: application/sparql-results+xml"
...
In the examples above I'm using only (for indexing and querying) the node running on localhost:8080 but you can send the query to any node in the cluster. For instance you can re-execute the query above with the other node (assuming it is running on localhost:8081):
# curl "http://127.0.0.1:8081/solr/store/sparql" \
--data-urlencode "q=SELECT * WHERE { ?s ?p ?o } LIMIT 10" \
-H "Accept: application/sparql-results+json"
...
You will get the same results.
Is that ready for a production scenario? No, absolutely not. I think a lot needs to be done on indexing and querying optimization side. At the moment only the functional side has been covered: the integration test suite includes about 150 SPARQL queries (ASK, CONSTRUCT, SELECT and DESCRIBE) and updates (e.g. INSERT, DELETE) taken from the LearningSPARQL book [1], that are working regardless the target service is running as a standalone or clustered instance.
I will run the first benchmarks as soon as possible but honestly at the moment I don't believe I'll see high throughputs.
Best,
Andrea
[1] http://www.learningsparql.com